
Originally Posted on October 5th 2023
Since its release almost a year ago, ChatGPT has been hailed for its groundbreaking AI capabilities, a seemingly autonomous Chatbot developed through Machine Learning algorithms. However, there is a significant human component that sets it apart from other AI tools.
It is called Reinforcement Learning from Human Feedback
Described as “the novel technique that made ChatGPT exceptional”, it is profound how such a fundamental step in developing this pioneering AI assistant is performed manually by humans at computer terminals.
In this article I will provide a brief look at RLHF, specifically how a Human Trainer ensures the quality of responses through both a rewards based model and labelling out harmful data.
What is Reinforcement Learning from Human Feedback?
Reinforcement Learning is a ‘sub field’ of machine learning, whereby an agent (Chat GPT) learns a policy through an environment.
Reinforcement Learning from Human Feedback makes use of human ‘labelers’ who supervise and ultimately dictate whether an automated text response from ChatGPT is acceptable, thereby training the model on what content is desired.
How the system works
Chat GPT works on guessing missing tokens in a sequence or put more plainly, words in a sentence. There are two methods, one is Next-Word prediction, where as you guessed, the next word in the sequence/sentence is produced based on a probability score.
E.G
Open the pod bay doors,_____
- Now
- Hal
- Then
- Thank You
The other popular method that is employed is called Masked Text Modelling, whereby a word in the middle of a sentence or phrase is missing and the model guesses which word best suits the overall meaning. This method has the benefit of teaching the Chatbot how to produce coherent sentences and to understand the importance of context.
E.G
Open the pod _____ doors, Hal
- Bay
- Airlock
- Emergency
- Security
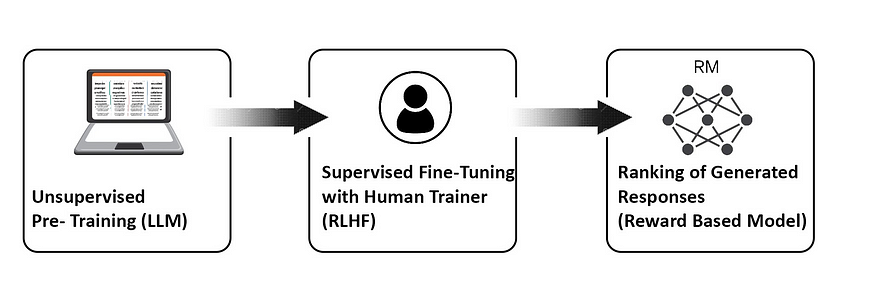
Pre-Training
At the first stage, a large language model like GPT-3 is Pre trained (that’s the P in GPT). It is here where the Chatbot is initially exposed to a large corpus of text data, literally hundreds of billions of words. The Chatbot trains on this enormous amount of data to learn precisely how to answer questions, generate responses to prompts, write in different styles, make lists, reference examples etc.
R&R : Ranking and Rewards
After the Chatbot has gained a wide knowledge base in Pre-Training, it must now be refined or ‘fine-tuned’ by a group of human ‘data labelers’, this is where RLHF comes in.
Here the Chatbot is given a series of small, specific tasks to improve it’s performance:
- A Prompt or Query is input into the system, sometimes this is taken from actual user entries
- Then the model generates several responses that are ranked by the labeller to reflect human preferences/bias.
“The compilation of prompts from the OpenAI API and hand-written by labelers resulted in 13,000 input/output samples to leverage for the supervised model.” Source
Sometimes this stage can even involve data labelers playing the part of the AI assistant, manually typing out responses to be used as comparison data for the auto generated responses to measure up to. With more and more comparison data to work with, the model understands the policy better and can align their responses closer to the user’s intent, resulting in better token predictions.
The responses are ranked and are given rewards based on the quality of the responses. The bot then updates it’s parameters based on the supervised ‘Question and Answer’ dataset and its subsequent Reward based model.
Human Data Labelling
The other key task performed by humans in training the Chat GPT-3 Model is Data Labelling
A Time magazine investigation discovered that the San Francisco firm, Sama, had outsourced crucial Data Labelling work for Chat GPT to a group of workers in Kenya earning just $2 an hour. Their role involved filtering out hate speech and graphic content by labelling and classifying thousands of snippets of text data so that it is no longer generated in ChatGPT responses.
Bottleneck
However, a ‘bottleneck’ can occur when Machine Learning Pipelines rely on human labour, they of course cannot keep up with a bot; hence why there are both manual and automated ranking/reward signals. The upvote/downvote feature and the comment/feedback options can act as additional Human Supervision from the users themselves, flagging any suspicious or false outputs from the Chatbot.
Complete Autonomy?
ChatGPT is not completely autonomous at the moment. Amongst all the algorithms, it still requires humans to pick up on errors and prevent false, misleading and even toxic content from being generated by the bot. The dependence on a large human labour force to maintain Chat GPT is rarely acknowledged, making the pioneering AI platform appear more intelligent and self-reliant than it actually is.
Behind the curtain, there still remains an indispensable, human workforce working to keep AI safe for public use.
While completely unsupervised machine learning may be the ultimate goal, a human keeping watch may not be considered such a drawback but act as a reassurance to those still concerned about how AI may act if left completely to its own judgement.

Leave a Reply